
 Travel back in time and visit that old website you’ve been wondering about.
Travel back in time and visit that old website you’ve been wondering about.
If a tree falls in a forest, does it really make a sound? And if a website changes overnight, did its previous homepage ever really exist in the first place? Because so much of our world is increasingly digital – and ephemeral – it’s not just a philosophical question, it’s also a simple matter of history. That’s why the Wayback Machine, which features snapshots of websites as they age and change, is such a fascinating glimpse into the dusty corners of the web.
The Wayback Machine is a massive digital archive meant to preserve webpages that would otherwise be permanently lost to time. Without this hoard of data, every time a page was updated or deleted, it would simply vanish, as if it was never there.
The average life expectancy of a webpage is about 100 days, Mark Graham, director of the Wayback Machine, noted in a 2016 Entrepreneur article. There are a multitude of reasons why these webpages disappear. Site creators move on to other projects. Web hosting companies go bankrupt. Or maybe the page is moved or replaced with new data and content.
Advertisement
How the Wayback Machine Got Started
The Wayback Machine is the brainchild of Brewster Kahle and Bruce Gilliat, who also founded the Internet Archive, a digital library of websites, books, audio and video recordings and software programs. Both projects are San Francisco-based nonprofits. The Wayback Machine is a project of the Internet Archive. (Kahle and Gilliat also created Alexa Internet which analyzes web traffic patterns and was sold to Amazon.)
"They [Kahle and Gilliat] had started to archive webpages in 1996, and in 2001 launched the Wayback Machine to support discovery and playback of those archived web resources," says Graham in a recent email interview. "And, yes, the name was inspired by the 1960s cartoon series ‘The Rocky and Bullwinkle Show.’ In the cartoon the WABAC Machine (note the spelling difference) was a plot device used to transport the characters Mr. Peabody and Sherman back in time to visit important events in human history."
In a world where there are more than 1.7 billion websites, with the number climbing dramatically by the day, how can anyone possibly hope to catalog so many webpages? The Wayback Machine uses what are called "crawlers," a type of software that automatically moves through the web, taking snapshots of billions of sites as it goes. Some of the process is automated, but many of the requests are generated manually by a network of librarians, who prioritize certain types of sites that they think are important to preserve for posterity and for future generations.
The crawlers don’t capture every iteration of sites. The frequency of snapshots differs by the site’s importance – very significant sites might be recorded every few hours. Others might be logged weeks or months apart. Most aren’t logged at all (so don’t worry, that embarrassing fan website you made in high school is probably long gone by now). Wayback Machine aims to capture snapshots of important content, say, the breaking news headlines created by major media companies.
Furthermore, it doesn’t necessarily recreate the entire site, and it doesn’t preserve the data in a way that you’d experience it with your browser. It may only capture a few images of a few pages, and not preserve content that’s linked to other sites outside the domain.
Advertisement
Using the Wayback Machine
You’ve probably had the experience of clicking on a link on a webpage and getting a "404" or "page not found" notation. Now you’re wondering what was on the page originally. That’s where the Wayback Machine can help.
To use the Wayback Machine, go to https://archive.org/web/. Type the URL of the site you want to investigate in the "Browse History" search bar. We’ll use our favorite website https://www.howstuffworks.com/ for our example. In the results, you’ll see a chronological bar graph that shows how many times the site was crawled (and saved) in a given year.
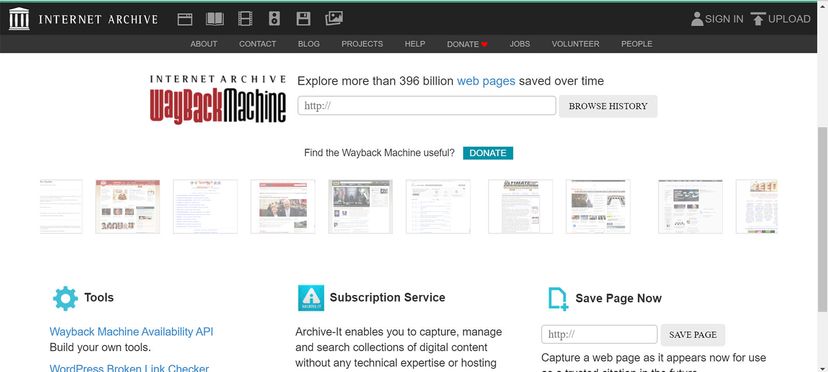 The homepage of the Wayback Machine website.
The homepage of the Wayback Machine website.
Click the year and below, you’ll see a 12-month calendar with various dates highlighted. Blue highlights mean the site was saved properly; red means it was not. Click one of the highlighted dates and the site’s snapshots will appear. Click on one of those snapshots and – just like that – you’ve traveled back in time to that older version of the site.
If you want to make sure that a particular site is recorded to the archive, you can do so manually. Use the Save Page now option to save a specific page once — but realize that doing so only saves that one page (not an entire website) and it doesn’t guarantee that the site will be crawled in the future.
And, if content owners want their material excluded from the Wayback Machine, they can submit a request by sending an email to info@archive.org.
You can also search books, videos, audio recordings and software programs by clicking on the icons at the top of the Wayback Machine homepage, next to the words "Internet Archive." These can be downloaded permanently or borrowed for a period, depending on the item. Advanced search features are also available.
Advertisement
The Future of the Wayback Machine
Graham says the most amazing thing about the Wayback Machine is that it exists at all and how much of the public web it is able to preserve, given that it has a small team and budget. (They do use volunteers as well.)
"With more support we can do an [even] better job of backing up more of the public web," he says. "Funding for the Internet Archive comes from a combination of ‘earned income’ from our subscription-based web-arching service, Archive-It.org, major donors and foundations, as well as contributions from more than 100,000 individual donors. We love being able to give away our services and don’t runs ads on our webpages."
He’s sure that the Wayback Machine will become even more important in the the future.
"As the nature of how people communicate and share information evolves, so too, we will need to build technologies, processes and partnerships to continue to do the best job we can to preserve as much of this public information as possible," he says. "All in support the Wayback Machine’s mission to ‘Help make the web more useful and reliable’ and, in particular to help support journalists, activists, academics, histories, researchers and the general public."
Editor’s note: The 13th paragraph of this article has been updated at the request of the Wayback Machine staff.
Now That’s Interesting
Mark Graham says that more than 11 million webpages referenced in Wikipedia articles have gone bad over the years (in other words, they now return a 404 or "Page not found"). Because they had been archived in the Wayback Machine, techs there were able to edit those Wikipedia pages, so the references now point to archived versions of those defunct URLs.
Advertisement


